When not to use AI
Generative AI is a powerful tool—but only if you know when not to use it. In this post, we explore a simple model that helps you decide whether AI will boost your testing or lead you off track.


Welcome back to another in a series of posts that follow up on questions I’ve been asked during AMA sessions on the subject of Generative AI and testing. This will be my final AMA post for now, so what better question to conclude with than:
When should we not use AI?
Through the past few posts on Gen AI, I’ve demonstrated different ways in which AI might help. However, it’s equally important to discuss instances where Gen AI may not be the most suitable option. So let’s explore when not to use AI in a way that focuses not on criticising AI, but on understanding our abilities and relationship with Gen AI as we use it.
Understanding types of activities
Spend more than five minutes on a site like LinkedIn and you’ll likely see a comparison between ‘manual’ and ‘automated’ testing. Some advocates for AI tend to focus on how AI is best used for ‘automated’ testing activities, and less so for ‘manual’ testing. The problem, though, is that this lens on testing hides the fact that not all aspects of ‘automation’ are easily dealt with with AI, and misses opportunities for AI use in the ‘manual’ space.
Instead, when considering opportunities for AI, I draw on Nicholas Carr’s distinction of tasks being either ‘algorithmic’ or ‘heuristic’ based. An approach he lays out in his book ‘The Glass Cage’, which explores how automation impacts individuals and society. Simply put, algorithmic tasks can be explicitly described in a step-by-step manner. So, for example, writing a test case and following it to the letter would be an algorithmic task (Notice how there is no mention of automation here). A heuristic-based task is harder to define and more rooted in our tacit and implicit understanding of problem solving. A good example of this might be identifying a bug based on oracles or coming up with a test idea during an exploratory testing activity.
What makes these distinctions useful is that when we look at a testing activity like test automation, we can break it down to identify both Algorithmic and heuristic-based tasks. An algorithmic task might benefit from the use of AI, for example, to generate code or test data. A heuristic task relies more on our abilities to design our code and determine what assertions are best to use to confirm system behaviour.
Shaping AI use based on our experience
Does this mean that we should only use AI for algorithmic tasks? It’s not a bad rule to follow, but to be honest, it’s a bit of an oversimplification. This is because Generative AI can also offer support with tasks that lean more towards the heuristic category.
Take, for example, the generation of test cases. We can feed Generative AI a prompt with some requirements and instructions to generate test cases, and it will build them for us. In our prompt, we likely didn’t set out all the rules and procedures to follow to generate test cases, but generate them it will. Some might be useful, some not. To be clear, I’m not saying that Generative AI is, at this time, as capable as a human in solving heuristic-based tasks. But the predictive nature of an LLM can give its responses the illusion that it can solve heuristic-based tasks. We can either provide an AI with algorithmic steps to follow or some loose instructions that require more heuristic-based problem solving, and in both situations, an LLM might deliver a valuable response. With this in mind, we can assume that heuristic-based tasks are also candidates for AI use. But it’s important to keep in mind that whilst we don’t have to explicitly describe each step the AI has to carry out to get a result, we do need to make sure that the output from an AI delivers us an expected response.
Which begs the question. How do you know if an LLM’s response is correct? When it comes to algorithmic tasks, the explicitly communicated steps themselves can be used to evaluate the outcome. However, with heuristic-based tasks, there may be no explicit information available to determine if an outcome is successful or not. Instead, we have to rely on our own experiences and intuition. With this in mind, let’s return to the question of when we should and shouldn’t use AI by graphing the type of task based on our experience around the task:
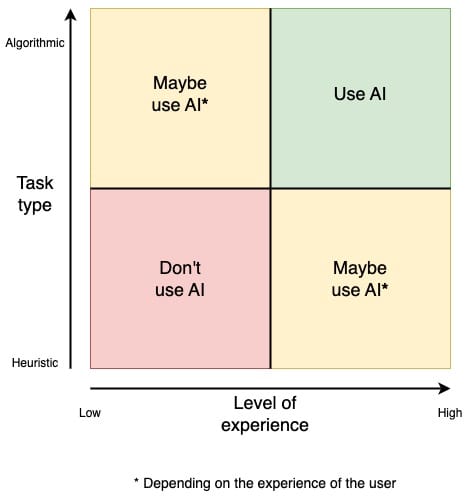
As we can see, the spectrum of when to and when not to use AI is on a scale. If the task we want to use AI for is easy to communicate and we have strong prior experience with it, then it’s a strong candidate. On the other side of the scale, if we know very little about the activity, what good looks like and can’t easily communicate steps, then it’s one to avoid. The other quadrants demonstrate that the boundary between those two is blurry. What I hope this graph demonstrates is that we have a responsibility to understand our relationship in the task we want AI to carry out. It would be unethical to use AI in areas that we can neither describe clearly nor be able to judge competently. These are the areas that we must avoid. Focusing on building up our understanding before utilising AI.
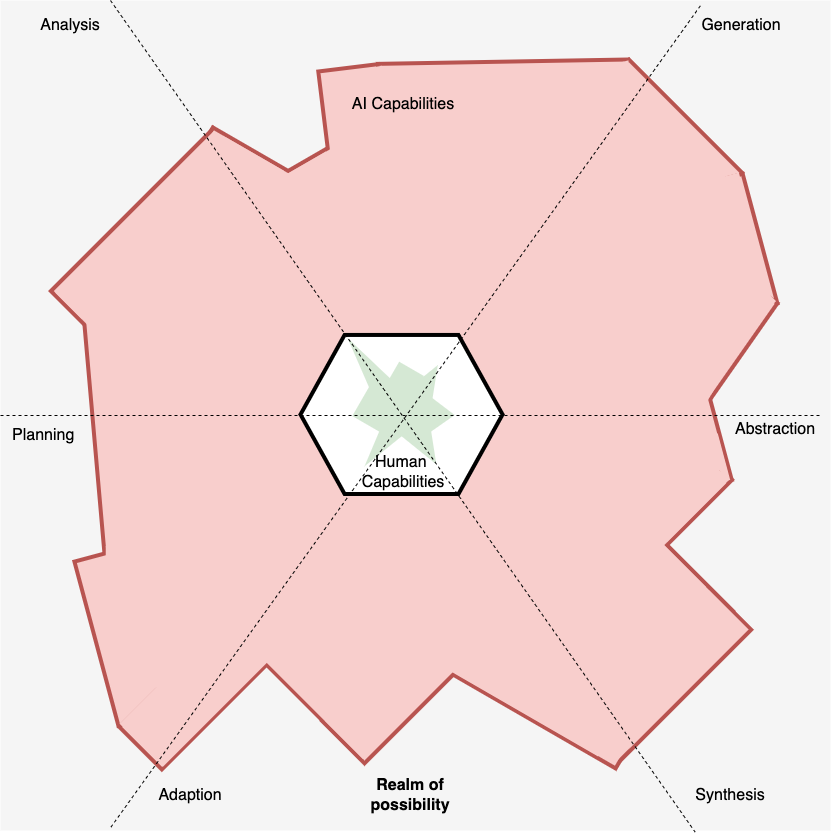
This is why I created the ‘Area of Effect’ model. Not just to communicate the relationship between individuals and AI and their capabilities and values, but to help us appreciate that we all have our strengths and weaknesses within it. I may feel confident in getting an AI to help suggest complex test design ideas because I have experience with test design and the context I’m working in. However, using it to develop an API that handles authentication, when I have very little experience in that space, would be foolish. Meaning that the question of when not to use AI is going to be different for each of us, but we all must work that out for ourselves.
Conclusion
When should and shouldn’t we use AI? What I hope this post highlights is that we should avoid using AI in areas where we are either unable to:
- Explicitly describe the steps that need to be carried out during an activity.
- We are unable to determine if the output from an activity matches our expectations correctly (Regardless of whether we can communicate the activity steps or not).
Successful use with AI comes from a symbiosis of AI capability and human experience. If we begin to defer activities to AI that we are unable to either explicitly define or judge the output of, then we are at risk of being steered off course by misleading or outright hallucinated outputs. Which, at best, will slow us down and, at worst, result in delivering low-quality or potentially dangerous work. In a nutshell, if you don’t know the area that you are using AI for well enough to determine if an output is of low value, then it’s best to steer clear of it until you have more experience in that space. Meaning that we each individually have to reflect on our skills and experiences to better appreciate when AI should and should not be used.